调度器是编排工具的核心,调度策略和算法是编排工具的灵魂。Kubernetes之所以能够大行其道,正是因为其优良的调度算法,本文就来分析下kubernets中scheduler组件的调度原理。
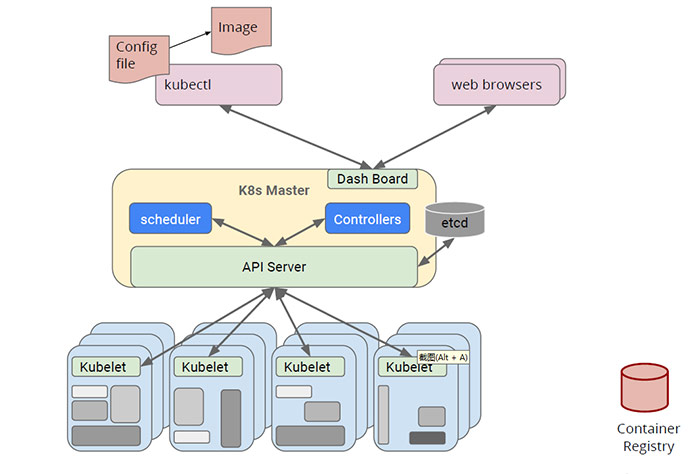
调度是Kubernetes集群中进行容器编排工作最重要的一环,在Kubernetes中,Controller Manager负责创建Pod,Kubelet负责执行Pod,而Scheduler就是负责安排Pod到具体的Node,它通过API Server提供的接口监听Pod任务列表,获取待调度pod,然后根据一系列的预选策略和优选策略给各个Node节点打分,然后将Pod发送到得分最高的Node节点上,由kubelet负责执行具体的任务内容。架构流程如下:
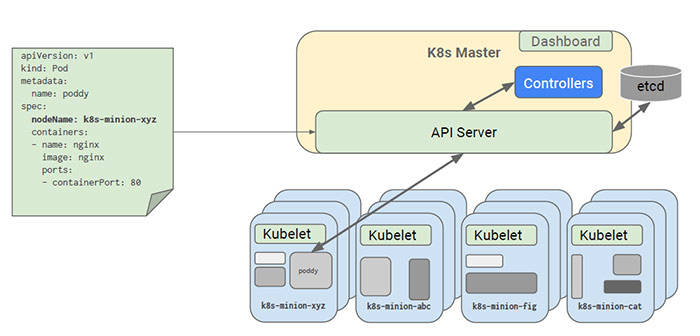
有个特例:如果Pod中指定了NodeName属性,则Scheduler调度器无需参与,Pod会直接发送到NodeName指定的Node节点:
1 调度策略
Kubernetes的调度策略分为Predicates(预选策略)和Priorites(优选策略),整个调度过程分为两步:
1.预选策略,Predicates是强制性规则,遍历所有的Node节点,按照具体的预选策略筛选出符合要求的Node列表,如没有Node符合Predicates策略规则,那该Pod就会被挂起,直到有Node能够满足。
2.优选策略,在第一步筛选的基础上,按照优选策略为待选Node打分排序,获取最优者。
1.1 预选策略
随着版本的演进Kubernetes支持的Predicates策略逐渐丰富,v1.0版本仅支持4个策略,v1.7支持15个策略,Kubernetes(v1.7)中可用的Predicates策略有:
- MatchNodeSelector:检查Node节点的label定义是否满足Pod的NodeSelector属性需求
- PodFitsResources:检查主机的资源是否满足Pod的需求,根据实际已经分配(Limit)的资源量做调度,而不是使用已实际使用的资源量做调度
- PodFitsHostPorts:检查Pod内每一个容器所需的HostPort是否已被其它容器占用,如果有所需的HostPort不满足需求,那么Pod不能调度到这个主机上
- HostName:检查主机名称是不是Pod指定的NodeName
- NoDiskConflict:检查在此主机上是否存在卷冲突。如果这个主机已经挂载了卷,其它同样使用这个卷的Pod不能调度到这个主机上,不同的存储后端具体规则不同
- NoVolumeZoneConflict:检查给定的zone限制前提下,检查如果在此主机上部署Pod是否存在卷冲突
- PodToleratesNodeTaints:确保pod定义的tolerates能接纳node定义的taints
- CheckNodeMemoryPressure:检查pod是否可以调度到已经报告了主机内存压力过大的节点
- CheckNodeDiskPressure:检查pod是否可以调度到已经报告了主机的存储压力过大的节点
- MaxEBSVolumeCount:确保已挂载的EBS存储卷不超过设置的最大值,默认39
- MaxGCEPDVolumeCount:确保已挂载的GCE存储卷不超过设置的最大值,默认16
- MaxAzureDiskVolumeCount:确保已挂载的Azure存储卷不超过设置的最大值,默认16
- MatchInterPodAffinity:检查pod和其他pod是否符合亲和性规则
- GeneralPredicates:检查pod与主机上kubernetes相关组件是否匹配
- NoVolumeNodeConflict:检查给定的Node限制前提下,检查如果在此主机上部署Pod是否存在卷冲突
已注册但默认不加载的Predicates策略有:
- PodFitsHostPorts
- PodFitsResources
- HostName
- MatchNodeSelector
PS:此外还有个PodFitsPorts策略(计划停用),由PodFitsHostPorts替代
1.2 优选策略
同样,Priorites策略也在随着版本演进而丰富,v1.0版本仅支持3个策略,v1.7支持10个策略,每项策略都有对应权重,最终根据权重计算节点总分,Kubernetes(v1.7)中可用的Priorites策略有:
- EqualPriority:所有节点同样优先级,无实际效果
- ImageLocalityPriority:根据主机上是否已具备Pod运行的环境来打分,得分计算:不存在所需镜像,返回0分,存在镜像,镜像越大得分越高
- LeastRequestedPriority:计算Pods需要的CPU和内存在当前节点可用资源的百分比,具有最小百分比的节点就是最优,得分计算公式:cpu((capacity – sum(requested)) * 10 / capacity) + memory((capacity – sum(requested)) * 10 / capacity) / 2
- BalancedResourceAllocation:节点上各项资源(CPU、内存)使用率最均衡的为最优,得分计算公式:10 – abs(totalCpu/cpuNodeCapacity-totalMemory/memoryNodeCapacity)*10
- SelectorSpreadPriority:按Service和Replicaset归属计算Node上分布最少的同类Pod数量,得分计算:数量越少得分越高
- NodePreferAvoidPodsPriority:判断alpha.kubernetes.io/preferAvoidPods属性,设置权重为10000,覆盖其他策略
- NodeAffinityPriority:节点亲和性选择策略,提供两种选择器支持:requiredDuringSchedulingIgnoredDuringExecution(保证所选的主机必须满足所有Pod对主机的规则要求)、preferresDuringSchedulingIgnoredDuringExecution(调度器会尽量但不保证满足NodeSelector的所有要求)
- TaintTolerationPriority:类似于Predicates策略中的PodToleratesNodeTaints,优先调度到标记了Taint的节点
- InterPodAffinityPriority:pod亲和性选择策略,类似NodeAffinityPriority,提供两种选择器支持:requiredDuringSchedulingIgnoredDuringExecution(保证所选的主机必须满足所有Pod对主机的规则要求)、preferresDuringSchedulingIgnoredDuringExecution(调度器会尽量但不保证满足NodeSelector的所有要求),两个子策略:podAffinity和podAntiAffinity,后边会专门详解该策略
- MostRequestedPriority:动态伸缩集群环境比较适用,会优先调度pod到使用率最高的主机节点,这样在伸缩集群时,就会腾出空闲机器,从而进行停机处理。
已注册但默认不加载的Priorites策略有:
- EqualPriority
- ImageLocalityPriority
- MostRequestedPriority
PS:此外还有个ServiceSpreadingPriority策略(计划停用),由SelectorSpreadPriority替代
2 结语
Kubernetes的Scheduler调度器提供了如此大量的调度策略,灵活搭配使用它们,能够应对各种各样的需求场景。尤其是在大型集群环境中,优秀的调度策略和算法,可以为业务提供稳定高效的运行时环境。
版权声明:允许转载,请注明原文出处:http://cloudnil.com/2017/06/06/Schedule-principle/。